Script encargado de recorrer categorías, procesar fichas de producto, descargar imágenes y documentación técnica y generar los archivos de importación.
import requests
import urllib.parse
import os
import itertools
from itertools import product
from itertools import zip_longest
import re
from time import sleep, time
from playwright.sync_api import sync_playwright, TimeoutError as PWTimeoutError
import csv
import sys
import io
from hashlib import sha1
import random
import json
import math
# ==========================
# Config de cookies importadas
# ==========================
USE_IMPORTED_COOKIES = True
COOKIES_PATH = "cookies_chrome.json" # <-- tu archivo exportado del navegador
BROWSER_UA = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/144.0.0.0 Safari/537.36" # opcional: pon aquí el UA EXACTO de tu navegador para mejorar compatibilidad (o deja None)
ENLACES_FILE = "enlaces_procesados.txt"
# ==========================
# Utilidades anti-baneo
# ==========================
UAS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.6723.91 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 14_1_1) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/18.1 Safari/605.1.15",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.6668.100 Safari/537.36",
]
def is_blocked(page):
try:
title = (page.title() or "").lower()
except Exception:
title = ""
try:
html = (page.content()[:1500] or "").lower()
except Exception:
html = ""
tokens = ["just a moment", "cloudflare", "cf-challenge", "checking your browser", "access denied"]
return any(tok in title or tok in html for tok in tokens)
def jitter_sleep(min_ms=1200, max_ms=3000):
sleep(random.uniform(min_ms, max_ms) / 1000.0)
def new_context_with_stealth(browser, storage_path="state.json", use_storage=True, ua_override=None):
ua = ua_override or random.choice(UAS)
kwargs = {
"user_agent": ua,
"locale": "es-ES",
"timezone_id": "Europe/Madrid",
"viewport": {"width": 1366, "height": 800},
"extra_http_headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Accept-Language": "es-ES,es;q=0.9,en;q=0.8",
"Upgrade-Insecure-Requests": "1",
},
}
if use_storage and os.path.exists(storage_path):
kwargs["storage_state"] = storage_path
ctx = browser.new_context(**kwargs)
# Ocultar señales de automatización
ctx.add_init_script("""
Object.defineProperty(navigator, 'webdriver', {get: () => undefined});
Object.defineProperty(navigator, 'languages', {get: () => ['es-ES','es']});
Object.defineProperty(navigator, 'plugins', {get: () => [1,2,3]});
window.chrome = { runtime: {} };
""")
return ctx
def safe_goto(page, url, retries=2, wait_after_ms=4000):
for attempt in range(retries + 1):
try:
page.goto(url, timeout=45000, wait_until="domcontentloaded")
page.wait_for_timeout(wait_after_ms + random.randint(0, 2000))
if not is_blocked(page):
return True
except PWTimeoutError:
pass
# Backoff exponencial + jitter
backoff = (2 ** attempt) * 10 + random.randint(5, 12)
print(f"🚫 Bloqueado o timeout en {url} (intento {attempt+1}/{retries+1}). Esperando {backoff}s…")
sleep(backoff)
return False
def accept_cookies_if_any(page):
for s in [
"#CybotCookiebotDialogBodyLevelButtonLevelOptinAllowAll",
'button:has-text("Aceptar")',
'button:has-text("Aceptar todas")',
'button:has-text("Accept all")',
]:
try:
page.locator(s).first.click(timeout=1500)
print("Cookies aceptadas ✅")
return
except Exception:
pass
def get_max_pages(page):
# 1) Etiqueta original
try:
el = page.query_selector('.label.cs-pagination__page-provider-label')
if el:
txt = el.inner_text().strip()
m = re.search(r"(\d+)\s*$", txt) or re.search(r"de\s+(\d+)", txt, re.I)
if m:
return int(m.group(1))
except Exception:
pass
# 2) Enlaces '?p='
try:
nums = page.eval_on_selector_all(
"a[href*='?p='], li a[href*='?p=']",
"""els => els.map(e => {
const m = (e.href.match(/\\?p=(\\d+)/) || [])[1];
return m ? parseInt(m) : null;
}).filter(Boolean)"""
)
if nums:
return max(nums)
except Exception:
pass
# 3) Fallback
return 1
def extract_listing_hrefs(page):
# Scroll suave para lazy
try:
page.mouse.wheel(0, random.randint(900, 2200))
jitter_sleep(600, 1200)
except Exception:
pass
selector_union = ",".join([
"a.cs-product-tile__thumbnail-link.product-item-photo",
"a.product-item-link",
".product-item a[href]"
])
try:
hrefs = page.eval_on_selector_all(
selector_union,
"""els => Array.from(new Set(els.map(e => e.href).filter(Boolean)))"""
)
except Exception:
hrefs = []
print(f" - Encontrados {len(hrefs)} enlaces en el listado")
if not hrefs:
counts = {}
for s in selector_union.split(","):
s = s.strip()
try:
counts[s] = page.locator(s).count()
except Exception:
counts[s] = 0
print(" - Conteo por selector:", counts)
return hrefs
def limpiar_precio(precio: str) -> float:
precio = precio.replace("\u00a0", " ").strip()
limpio = re.sub(r"[^\d,\.]", "", precio)
if "," in limpio and limpio.count(",") == 1 and limpio.rfind(",") > limpio.rfind("."):
limpio = limpio.replace(".", "").replace(",", ".")
else:
limpio = limpio.replace(",", "")
return float(limpio)
# --- añade esto cerca de tus utilidades ---
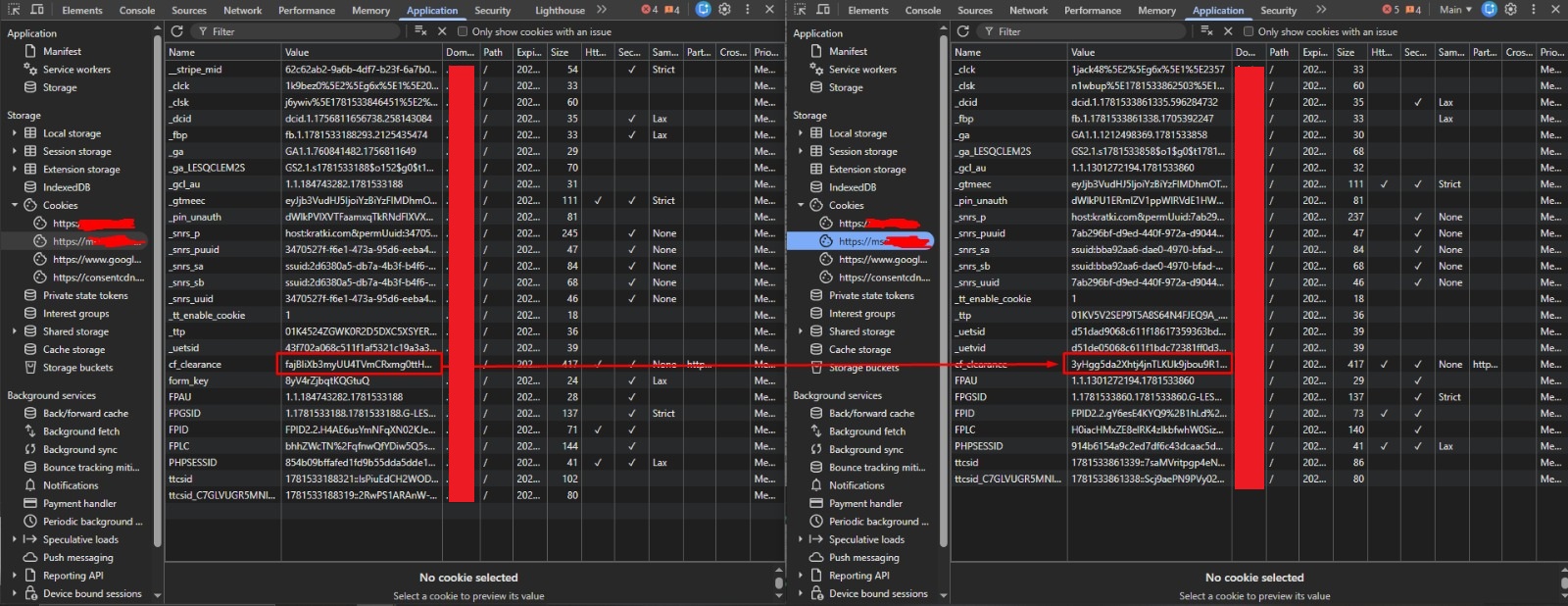
def handle_cloudflare_block(page, ctx, current_url, dominio="testweb.com"):
"""
Pausa, permite pegar manualmente la cookie cf_clearance, refresca y comprueba.
Devuelve True si se superó Cloudflare; False si el usuario decide saltar.
"""
print("\n🚧 Cloudflare detectado en:", current_url)
print("Abre el sitio en tu navegador normal, pasa el reto y copia el valor de la cookie 'cf_clearance'")
print("Chrome: F12 -> Application -> Storage -> Cookies ->", dominio)
print("Pega solo el valor (no 'cf_clearance='). Deja vacío y pulsa Enter para saltar esta página.\n")
while True:
val = input("Pega cf_clearance y pulsa Enter (vacío = saltar): ").strip()
if not val:
print("⏭️ Saltando esta página.")
return False
# Inyectar cookie (como sesión; Cloudflare ya define la expiración internamente)
try:
ctx.add_cookies([{
"name": "cf_clearance",
"value": val,
"domain": dominio, # sin el punto inicial
"path": "/",
"httpOnly": True,
"secure": True,
"sameSite": "Lax"
}])
except Exception as e:
print("⚠️ Error al añadir cookie:", e)
# Refrescar la URL donde estábamos y re-comprobar
try:
page.goto(current_url, wait_until="domcontentloaded", timeout=60000)
page.wait_for_timeout(2000)
except Exception:
pass
if not is_blocked(page):
print("✅ Cloudflare superado con la cookie manual. Continuando…")
# guardamos estado por si la cookie caduca más adelante
try:
ctx.storage_state(path="state.json")
except Exception:
pass
return True
else:
print("❌ Sigue bloqueado. Prueba a pegar otra cookie (asegúrate de mismo IP/UA).")
def goto_must_load(page, ctx, url, max_retries=8):
attempt = 0
while True:
try:
print(f"🌐 Cargando ({attempt+1}/{max_retries}) {url}")
page.goto(url, wait_until="domcontentloaded", timeout=60000)
page.wait_for_timeout(2500)
if not is_blocked(page):
return True
print("🚧 Bloqueo detectado (Cloudflare)")
ok = handle_cloudflare_block(page, ctx, url)
if ok:
return True
except PWTimeoutError:
print("⏳ Timeout, reintentando…")
attempt += 1
if attempt >= max_retries:
print("🛑 Demasiados intentos. Esperando 60s y reintentando…")
sleep(60)
attempt = 0 # 🔁 reset y seguimos
sleep(10 + random.randint(0, 10))
# ==========================
# Conversor: cookies navegador -> Playwright
# ==========================
def cookies_to_playwright(path, default_domain="testweb.com"):
with open(path, "r", encoding="utf-8") as f:
src = json.load(f)
out = []
for c in src:
name = c.get("name")
value = c.get("value")
if not name or value is None:
continue
domain = (c.get("domain") or default_domain).lstrip(".")
path = c.get("path") or "/"
httpOnly = bool(c.get("httpOnly", False))
secure = bool(c.get("secure", True))
ss = c.get("sameSite")
if ss is None:
sameSite = "Lax"
else:
ss_l = str(ss).lower()
if ss_l == "lax":
sameSite = "Lax"
elif ss_l == "strict":
sameSite = "Strict"
elif ss_l in ("none", "no_restriction"):
sameSite = "None"
else:
sameSite = "Lax"
exp = c.get("expirationDate")
if isinstance(exp, (int, float)):
expires = int(math.floor(exp))
else:
expires = None
item = {
"name": name,
"value": value,
"domain": domain,
"path": path,
"httpOnly": httpOnly,
"secure": secure,
"sameSite": sameSite
}
if expires:
item["expires"] = expires
out.append(item)
return out
# ==========================
# Salida UTF-8
# ==========================
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
# URLs y rutas
url = 'https://testweb.com/es/test'
rutaImagenes = r'C:\Users\ufo_51\Desktop\Imagenes'
if not os.path.exists(rutaImagenes):
os.makedirs(rutaImagenes)
rutaPDFs = r'C:\Users\ufo_51\Desktop\PDFs'
if not os.path.exists(rutaPDFs):
os.makedirs(rutaPDFs)
contadorImagenes = 0
contadorPDFs = 1384
idProducto = 4373
idCategoria = "3,196"
enlaces_procesados = set()
def normalizar_url(url):
if not url:
return None
url = url.split("#")[0]
url = url.split("?")[0]
return url.rstrip("/")
# Cargar enlaces procesados (persistente)
if os.path.exists(ENLACES_FILE):
with open(ENLACES_FILE, "r", encoding="utf-8") as f:
enlaces_procesados = set(l.strip() for l in f if l.strip())
print(f"🔁 Cargados {len(enlaces_procesados)} enlaces procesados desde {ENLACES_FILE}")
else:
enlaces_procesados = set()
print("🆕 No existe enlaces_procesados.txt, empezando desde cero")
def guardar_enlaces_procesados():
# Guarda de forma segura el set actual
with open(ENLACES_FILE, "w", encoding="utf-8") as f:
for e in sorted(enlaces_procesados):
f.write(e + "\n")
print(f"💾 Guardados {len(enlaces_procesados)} enlaces procesados en {ENLACES_FILE}")
test = 0
listaCombinaciones = []
listaPrecios = []
testeo = []
listaPreciosTextos = []
listacuak = []
listaNombreAtributos = []
listaPsAttachment = []
listaPsAttachmentLang = []
listaNombreArchivo = []
listaImagenProducto = []
listaEspecificaciones = []
listaNombreCombinaciones = []
listaCSVCombinaciones = []
lel = []
cuak = []
listaKik = []
testeos = []
# CSV para guardar productos
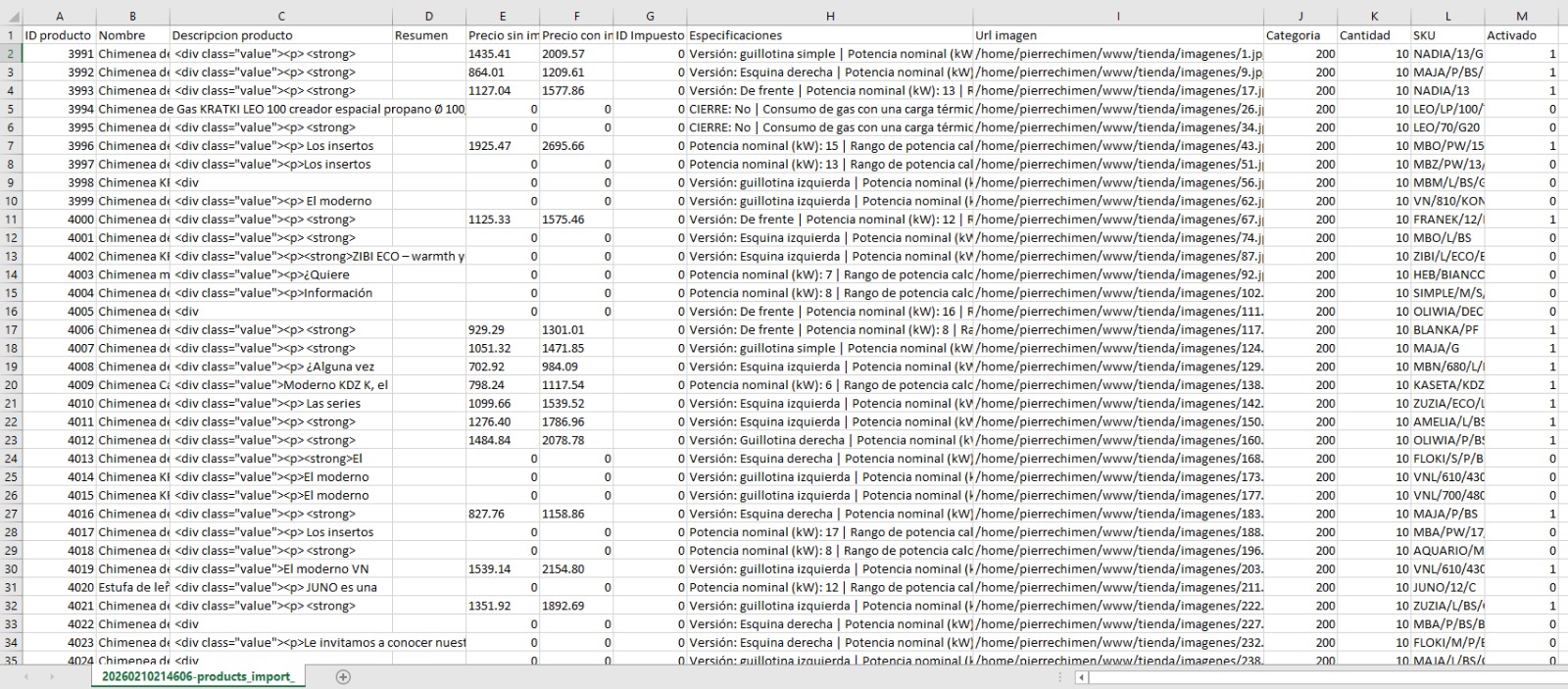
listacsvProductos = [['ID producto','Nombre','Descripcion producto','Resumen','Precio sin impuestos','Precio con impuestos','ID Impuesto','Especificaciones','Url imagen', 'Categoria', 'Cantidad', 'SKU']]
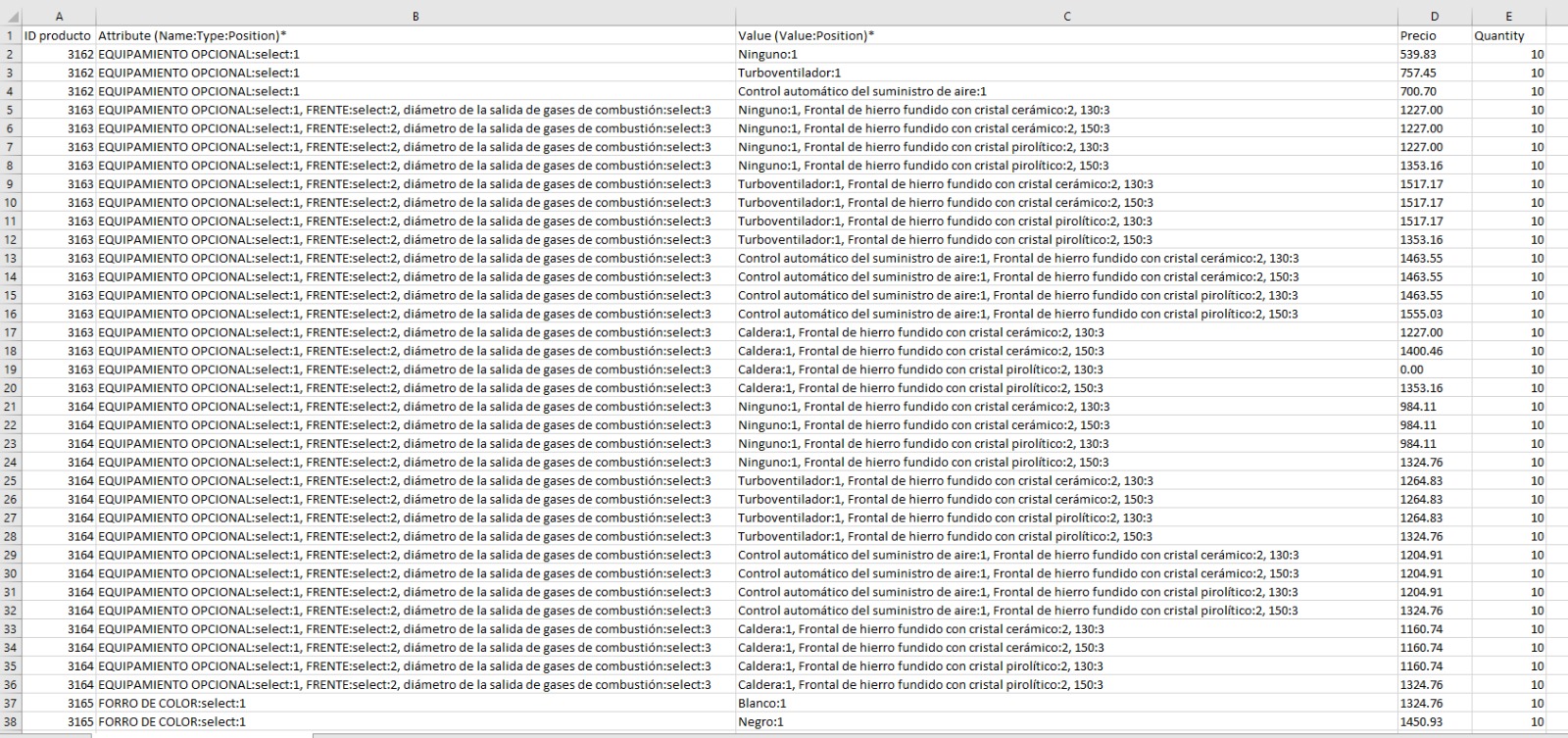
cuak = [['ID producto', 'Attribute (Name:Type:Position)*', 'Value (Value:Position)*', 'Quantity', 'SKU']]
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/144.0.0.0 Safari/537.36' }
# ==========================
# Ejecución Playwright
# ==========================
with sync_playwright() as p:
# Para depurar bloqueo, headless=False. Cuando vaya fino, puedes poner True.
browser = p.chromium.launch(headless=False, args=["--disable-blink-features=AutomationControlled"])
ctx = new_context_with_stealth(browser, storage_path="state.json", use_storage=True, ua_override=BROWSER_UA)
# (Opcional) Cargar cookies exportadas del navegador
if USE_IMPORTED_COOKIES and os.path.exists(COOKIES_PATH):
try:
cookies = cookies_to_playwright(COOKIES_PATH, default_domain="testweb.com")
if cookies:
ctx.add_cookies(cookies)
print(f"🍪 Cargadas {len(cookies)} cookies desde {COOKIES_PATH}")
except Exception as e:
print("⚠️ No se pudieron cargar las cookies importadas:", e)
page = ctx.new_page()
page.set_default_navigation_timeout(60000)
page.set_default_timeout(20000)
# ========= LISTADO PRINCIPAL =========
page.goto(url, timeout=60000, wait_until="domcontentloaded")
if is_blocked(page):
if not handle_cloudflare_block(page, ctx, url):
# si decides saltar el listado completo
pass
accept_cookies_if_any(page)
page.wait_for_timeout(1500)
page.wait_for_timeout(30000)
# Detectar páginas totales
max_pages = get_max_pages(page)
print("Páginas totales detectadas:", max_pages)
if not max_pages:
max_pages = 1
for i in range(1, max_pages + 1):
urlPages = f"{url}?p={i}"
page.goto(urlPages, timeout=60000, wait_until="domcontentloaded")
page.wait_for_timeout(2000)
print(f"Procesando {urlPages}...")
if is_blocked(page):
# reintento suave tuyo si quieres… y después:
ok = handle_cloudflare_block(page, ctx, urlPages)
if not ok:
print(" ❌ No se pudo pasar Cloudflare en esta página. La salto.")
#continue
hrefs = extract_listing_hrefs(page)
hrefs_unicos = []
for h in hrefs:
limpio = h
if limpio and limpio not in enlaces_procesados:
enlaces_procesados.add(limpio)
hrefs_unicos.append(limpio)
print(f" - Nuevos enlaces únicos: {len(hrefs_unicos)}")
# ========= DETALLE DE PRODUCTOS (SOLO NAVEGAR y esperar) =========
for j in hrefs_unicos:
idProducto += 1
enlace = j
if not enlace:
continue
dest_url = enlace if enlace.startswith("http") else f"https://testweb.com{enlace}"
# ✅ Carga SI O SI (reintenta y resuelve Cloudflare)
goto_must_load(page, ctx, dest_url)
page.wait_for_timeout(1500)
try:
tituloProducto = page.query_selector('.page-title > span')
descripcionProducto = page.query_selector('.product.attribute.description')
#precioProducto = page.query_selector('.price')
#disponibilidadProducto = page.query_selector('.cs-ask-for-product__span')
especificacionesProducto = page.query_selector_all("table.additional-attributes tr")
descargarPdfProducto = page.query_selector_all('.cs-pdp-documentation__item')
imagenesProducto = page.query_selector_all('.fotorama__stage__frame.fotorama_vertical_ratio.fotorama__loaded.fotorama__loaded--img > .fotorama__img')
resumenProducto = ""
sku_el = page.query_selector(".cs-pdp-info__row span:nth-of-type(2)")
if descripcionProducto:
descripcionProductoLimpio = descripcionProducto.inner_html()
print(descripcionProducto.inner_html())
else:
descripcionProductoLimpio = ""
pares = []
for row in especificacionesProducto:
th = row.query_selector("th")
td = row.query_selector("td")
if th and td:
key = th.inner_text().strip()
value = td.inner_text().strip()
listaEspecificaciones.append(f"{key}: {value}")
sku = sku_el.inner_text().strip() if sku_el else ""
print(tituloProducto.inner_text())
#print(limpiar_precio(precioProducto.inner_text()))
#if precioProducto:
#precioProductoConIVA = precioProducto.inner_text()
precioProductoConIVA = 0 #limpiar_precio(precioProductoConIVA)
precioProductoSinIVA = 0 #round(float(precioProductoConIVA) / 1.21, 2)
print(precioProductoConIVA)
print(precioProductoSinIVA)
especificacionesLimpio = " | ".join(map(str, listaEspecificaciones))
print(especificacionesLimpio)
# Esperar al banner de cookies (si aparece)
try:
page.wait_for_selector("#CybotCookiebotDialogBodyUnderlay", timeout=5000)
# Clic en el botón de "Aceptar todas las cookies"
page.click("#CybotCookiebotDialogBodyLevelButtonLevelOptinAllowAll", timeout=2000)
print("Cookies aceptadas ✅")
except:
print("No apareció el banner de cookies ❌")
page.wait_for_timeout(5000)
# Selector de la imagen
img_selector = ".fotorama__stage__frame.fotorama__loaded.fotorama__loaded--img.fotorama__active > .fotorama__img"
# Selector del botón next
next_selector = ".fotorama__arr.fotorama__arr--next"
miniaturas = page.query_selector_all('.fotorama__nav__frame.fotorama__nav__frame--thumb')
print(len(miniaturas))
imagenes = []
listaImagenProducto = []
if len(miniaturas) == 0:
img = page.query_selector(img_selector)
if img:
src = img.get_attribute("src")
contadorImagenes += 1
nombre_archivo = f"{contadorImagenes}.jpg"
ruta_destino = os.path.join(rutaImagenes, nombre_archivo)
# Descargar imagen
response = requests.get(src, headers={'User-Agent': 'Mozilla/5.0'})
if response.status_code == 200:
with open(ruta_destino, 'wb') as f:
f.write(response.content)
listaImagenProducto.append("/home/pierrechimen/www/tienda/imagenes/"+str(contadorImagenes)+".jpg")
else:
print(f"❌ Error {response.status_code} al descargar {src}")
else:
# Recorremos el slider
for i in miniaturas:
try:
page.wait_for_timeout(2000) # espera corta para cargar la imagen
img = page.query_selector(img_selector)
if img:
src = img.get_attribute("src")
contadorImagenes += 1
nombre_archivo = f"{contadorImagenes}.jpg"
ruta_destino = os.path.join(rutaImagenes, nombre_archivo)
# Descargar imagen
response = requests.get(src, headers={'User-Agent': 'Mozilla/5.0'})
if response.status_code == 200:
with open(ruta_destino, 'wb') as f:
f.write(response.content)
listaImagenProducto.append("/home/pierrechimen/www/tienda/imagenes/"+str(contadorImagenes)+".jpg")
else:
print(f"❌ Error {response.status_code} al descargar {src}")
# Avanzar al siguiente
page.click(next_selector)
except Exception as e:
print(f"❌ Error al descargar: {e}")
print("IMÁGENES ENCONTRADAS:")
for url in imagenes:
print(url)
imagenesProductoLimpio = " | ".join(map(str, listaImagenProducto))
#print(imagenesProductoLimpio)
for attacmentUrl in descargarPdfProducto:
print(attacmentUrl.get_attribute('href'), attacmentUrl.inner_text().strip().split("\n")[0])
urlPdf = attacmentUrl.get_attribute('href')
nombreArchivo = urlPdf.split("/")[-1]
# Descargar el PDF
response = requests.get(urlPdf, headers=headers, stream=True)
nombreArchivo = None
if "Content-Disposition" in response.headers:
content_disposition = response.headers["Content-Disposition"]
match = re.search(r'filename="?([^"]+)"?', content_disposition)
if match:
nombreArchivo = match.group(1)
# Si no vino en las cabeceras, usar el fallback con la URL
if not nombreArchivo:
nombreArchivo = urlPdf.split("/")[-1] or f"archivo_{int(time())}.pdf"
print("Nombre final:", nombreArchivo)
ruta_guardado = os.path.join("C:/Users/ufo_51/Desktop/pdf/", nombreArchivo)
now = time()
sha1Encriptado = sha1((str(now - int(now)) + ' ' + str(int(now))).encode()).hexdigest()
print(sha1Encriptado)
# Guardar en la ubicación elegida
with open(ruta_guardado, "wb") as archivo:
archivo.write(response.content)
os.rename(ruta_guardado, "C:/Users/ufo_51/Desktop/pdf/"+"\\"+sha1Encriptado)
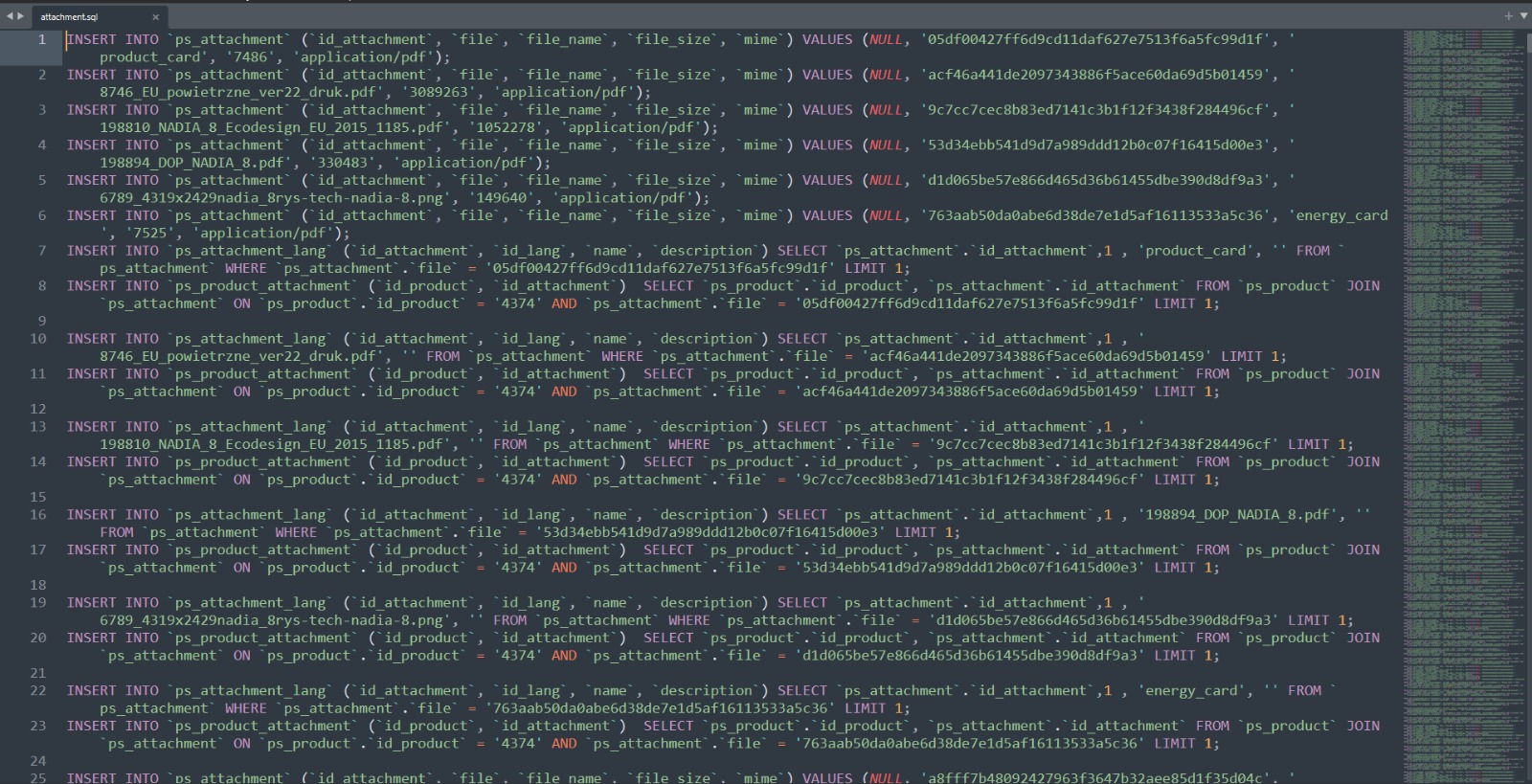
listaPsAttachment.append(", \'" + str(sha1Encriptado) + "', \'" + str(nombreArchivo) + "\', '" + str(os.path.getsize("C:/Users/ufo_51/Desktop/pdf/" + "\\" + sha1Encriptado)))
listaPsAttachmentLang.append(sha1Encriptado)
listaNombreArchivo.append(str(nombreArchivo))
id_lang = 0
for i in listaPsAttachment:
attachmentSQL = open("attachment.sql", 'a', encoding='utf8')
attachmentSQL.write(r"INSERT INTO `ps_attachment` (`id_attachment`, `file`, `file_name`, `file_size`, `mime`) VALUES (NULL" + str(i) + r"', 'application/pdf');" + '\n')
attachmentSQL.close()
listaPsAttachment.clear()
for b in zip(listaPsAttachmentLang, listaNombreArchivo):
id_lang += 1
attachmentSQL = open("attachment.sql", 'a', encoding='utf8')
attachmentSQL.write(r"INSERT INTO `ps_attachment_lang` (`id_attachment`, `id_lang`, `name`, `description`) SELECT `ps_attachment`.`id_attachment`,1 , '" + str(b[1]) + "', '' FROM `ps_attachment` WHERE `ps_attachment`.`file` = '" + str(b[0]) + r"' LIMIT 1;" + '\n')
attachmentSQL.write(r"INSERT INTO `ps_product_attachment` (`id_product`, `id_attachment`) SELECT `ps_product`.`id_product`, `ps_attachment`.`id_attachment` FROM `ps_product` JOIN `ps_attachment` ON `ps_product`.`id_product` = '" + str(idProducto) + "' AND `ps_attachment`.`file` = '" + str(b[0]) + "' LIMIT 1;" + '\n' + '\n')
attachmentSQL.close()
listaNombreArchivo.clear()
listaPsAttachmentLang.clear()
#INICIO - Guardarlo en el csv
listacsvProductos.append([idProducto, tituloProducto.inner_text(), descripcionProductoLimpio, resumenProducto, precioProductoSinIVA, precioProductoConIVA, "0", especificacionesLimpio, imagenesProductoLimpio,"200", "10", sku])
with open('products_import.csv', 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f, delimiter=';')
writer.writerows(listacsvProductos)
with open('combinaciones_import.csv', 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f, delimiter=';')
for fila in cuak:
# Suponiendo que cuak = [idProducto, listaNombreCombinaciones, item, "10"]
# Y que "item" es la columna C
if fila[2]: # Verifica si la columna C no está vacía
writer.writerow(fila)
guardar_enlaces_procesados()
#FIN - Guardarlo en el csv
print("--------------------")
#listaImagenProducto.clear()
listaEspecificaciones.clear()
except Exception as e:
print(f"Error en el producto {enlace}: {e}")
continue
# Ritmo humano entre páginas
jitter_sleep(5000, 10000)
# Guardar sesión/cookies para siguiente ejecución
ctx.storage_state(path="state.json")
ctx.close()
browser.close()